 EN
EN
 UK
UK
 RU
RU
 AR
AR
 BN
BN
 ZH
ZH
 DE
DE
 ES
ES
 FR
FR
 HI
HI
 ID
ID
 UR
UR
 PT
PT
 TR
TR

Working with spy tools usually starts with simple actions: searching creatives, filtering by geo, analyzing ad combinations. At this stage, it feels like the tool fully covers the task - data is accessible, results are consistent, and performance is sufficient.
But as the workload grows, system behavior begins to change. Automation is introduced, the number of requests increases, and multiple processes run in parallel. At some point, it becomes noticeable that results are no longer as consistent: some data fails to load, responses come with delays, and certain ad combinations simply disappear.
This is a common situation. And in most cases, the issue is not the spy tool itself, but how the workflow around it is structured.
Why issues appear as research expands
When ad research becomes more systematic, the nature of the load changes. Instead of isolated actions, dozens or even hundreds of requests are generated - especially when using API integrations and automation.
At this stage, several common patterns begin to appear:
identical or repeating IP usage
high request frequency without pauses
lack of proper load distribution
using a single configuration for all tasks
Each of these factors alone may seem insignificant. But together, they lead to the system behaving less consistently.
What this looks like in practice
In real workflows, issues appear gradually.
For example, when analyzing Facebook Ads, everything initially works correctly. You can switch between geos, explore creatives, and identify ad combinations. But once you open multiple tabs, actively refresh filters, and work in parallel, it becomes noticeable that some data loads more slowly.
The situation becomes more visible with automation. For instance, when collecting 200–300 creatives:
initial requests return accurate data
delays start to appear
some responses are incomplete
certain requests require retries
A similar pattern appears when working with TikTok Ads, especially across multiple geos. As a result, it may seem like there is less data available, while in reality the quality of access to data is changing.
How a stable workflow is built
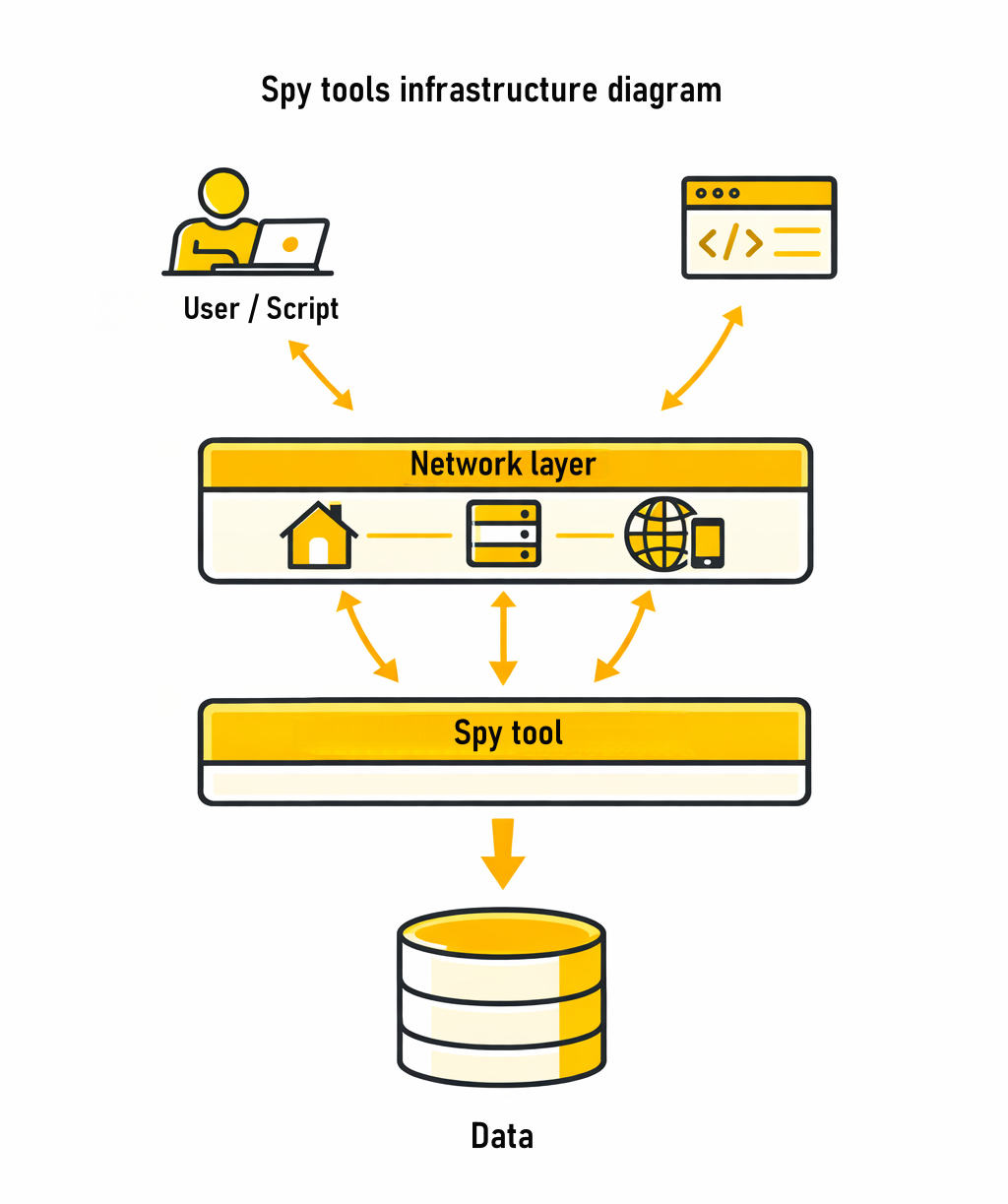
Stability does not come from a single tool, but from structure. In more mature setups, the approach to research itself changes. Instead of being a single action, it is divided into multiple stages - from initial filtering and analysis to data collection, repeated validation, and API workflows.
Each of these stages creates a different type of load, which is why they require different approaches to connections and request distribution. This separation is what allows the system to remain stable as volume grows.
Matching proxy types to tasks
One of the key factors is aligning proxy types with specific use cases.
In practice, workflows often rely on combinations:
residential proxies - for broad research and distributed data collection
ISP proxies - for stable sessions and repeated actions
datacenter proxies - for API calls and technical requests
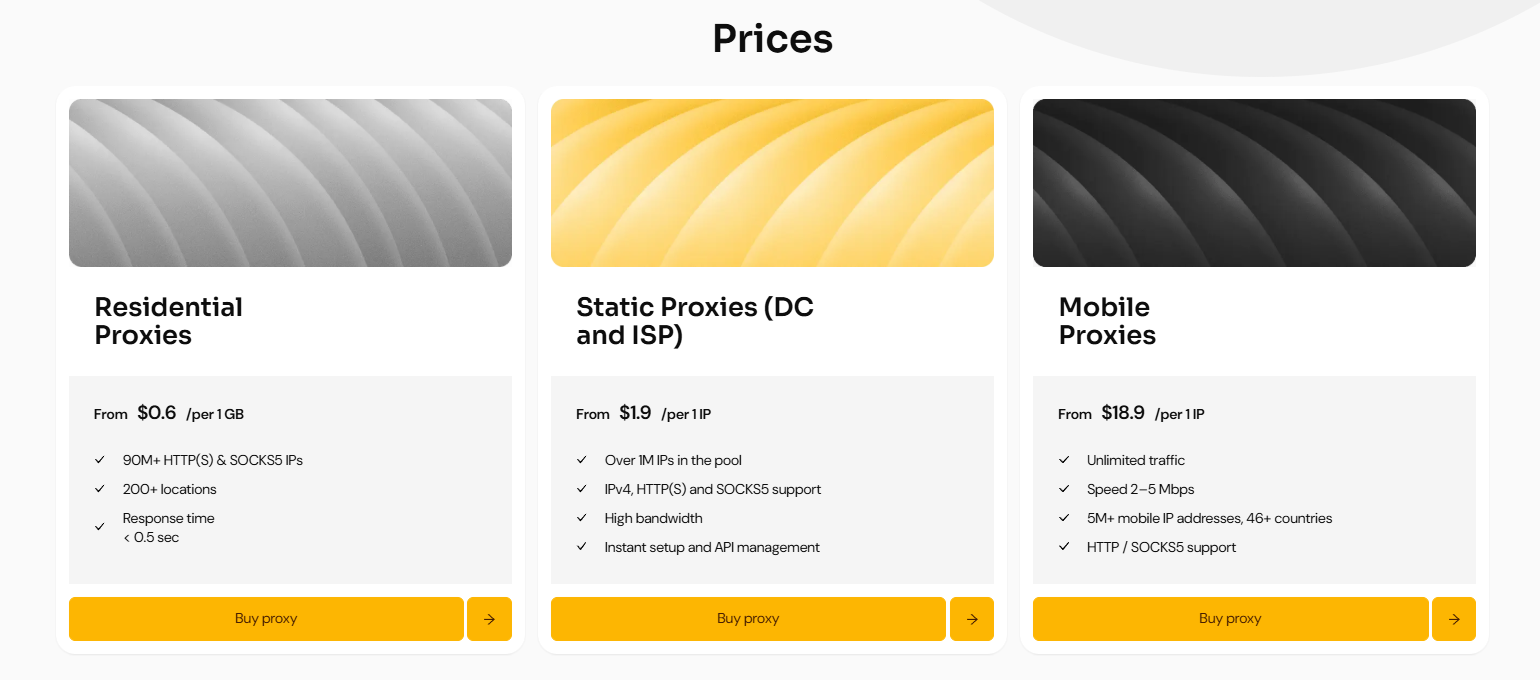
This separation helps avoid load conflicts and makes system behavior more predictable. For example, when working with MangoProxy, these scenarios can be managed within a single infrastructure without splitting processes across different services.
For tasks related to API and technical requests, static datacenter proxies can be used - with the promo code SPYHOUSE, a 15% discount is available.
Why simply increasing requests does not work
When data becomes insufficient, it is natural to try increasing the number of requests. However, without changing the logic, this usually leads to the opposite effect. Load starts to distribute unevenly. Some IPs become overloaded, traffic is used inefficiently, the number of repeated requests increases, and overall system stability decreases.
That is why the key factor is not volume, but control. What matters is how often requests are sent, how they are distributed across IP addresses, and how the rotation logic is structured. These parameters ultimately determine how stable the system will be as it scales.
The role of geography
Another important factor is geography.
In spy tools, data often depends on region, and this is especially noticeable when working with TikTok and push ads. If all requests come from a single location, some ad combinations may never appear in the results.
As research expands, this becomes critical.
That is why workflows often include regional distribution. Using proxies with global coverage allows you to:
compare results across different countries
identify local ad patterns
build a more complete view of the data
Practical conclusions
Expanding ad research is not about increasing activity, but about changing the approach. A stable system is built around several core principles: tasks are separated instead of being combined into a single process, connection types are matched to specific scenarios, load is controlled and distributed, and geography is taken into account.
In this context, proxies stop being a supporting tool and become part of the infrastructure. They directly influence how consistently and predictably the system performs as the workload grows.
FAQ
Why does data become less stable as request volume increases?
Because the nature of the load changes. Requests become more frequent and repetitive, and without proper distribution the system starts handling them less evenly.
Can one proxy type be used for everything?
Technically yes, but in practice this limits flexibility. Different tasks — such as manual analysis, parsing, and API usage — require different connection behavior.
Why does some data fail to load?
This is usually not an issue with the tool itself, but with overload or poor request distribution. When load is uneven, some connections degrade and affect data completeness.
Is geography important?
Yes. In spy tools, results often depend on region. Working from a single location may limit visibility of certain ad combinations.
Conclusion
As work with spy tools grows, both data volume and system requirements change. Stability is no longer a default characteristic - it becomes the result of architectural decisions. The way tasks are structured, load is managed, and traffic is distributed ultimately defines how effective ad research will be in the long term.


Comments 0