 FR
FR
 EN
EN
 UK
UK
 RU
RU
 AR
AR
 BN
BN
 ZH
ZH
 DE
DE
 ES
ES
 HI
HI
 ID
ID
 UR
UR
 PT
PT
 TR
TR

Travailler avec les outils de "spy" : de la recherche simple à l'infrastructure évolutive
Travailler avec les outils de spy commence généralement par des actions simples : recherche de créatives, filtrage par géo, analyse de combinaisons publicitaires. À ce stade, on a l'impression que l'outil couvre entièrement la tâche — les données sont accessibles, les résultats sont cohérents et les performances sont suffisantes.
Mais à mesure que la charge de travail augmente, le comportement du système commence à changer. L'automatisation est introduite, le nombre de requêtes augmente et plusieurs processus s'exécutent en parallèle. À un certain point, il devient notable que les résultats ne sont plus aussi constants : certaines données ne se chargent pas, les réponses arrivent avec du retard et certaines combinaisons publicitaires disparaissent tout simplement.
C'est une situation courante. Et dans la plupart des cas, le problème n'est pas l'outil de spy lui-même, mais la manière dont le flux de travail (workflow) autour de lui est structuré.
Pourquoi des problèmes apparaissent lors de l'extension de la recherche
Lorsque la recherche publicitaire devient plus systématique, la nature de la charge change. Au lieu d'actions isolées, des dizaines, voire des centaines de requêtes sont générées — surtout lors de l'utilisation d'intégrations API et de l'automatisation.
À ce stade, plusieurs schémas courants commencent à apparaître :
utilisation d'IP identiques ou répétitives
fréquence de requêtes élevée sans pauses
manque de distribution adéquate de la charge
utilisation d'une configuration unique pour toutes les tâches
Chacun de ces facteurs, pris isolément, peut sembler insignifiant. Mais ensemble, ils conduisent le système à se comporter de manière moins cohérente.
Ce que cela donne en pratique
Dans les flux de travail réels, les problèmes apparaissent progressivement.
Par exemple, lors de l'analyse des Facebook Ads, tout fonctionne correctement au début. Vous pouvez basculer entre les géos, explorer les créatives et identifier les combinaisons. Mais une fois que vous ouvrez plusieurs onglets, que vous actualisez activement les filtres et que vous travaillez en parallèle, il devient notable que certaines données se chargent plus lentement.
La situation devient plus visible avec l'automatisation. Par exemple, lors de la collecte de 200 à 300 créatives :
les requêtes initiales renvoient des données précises
des retards commencent à apparaître
certaines réponses sont incomplètes
certaines requêtes nécessitent des tentatives supplémentaires (retries)
Un schéma similaire apparaît lors du travail avec les TikTok Ads, en particulier sur plusieurs géos. En conséquence, il peut sembler qu'il y a moins de données disponibles, alors qu'en réalité, c'est la qualité de l'accès aux données qui change.
Comment construire un workflow stable
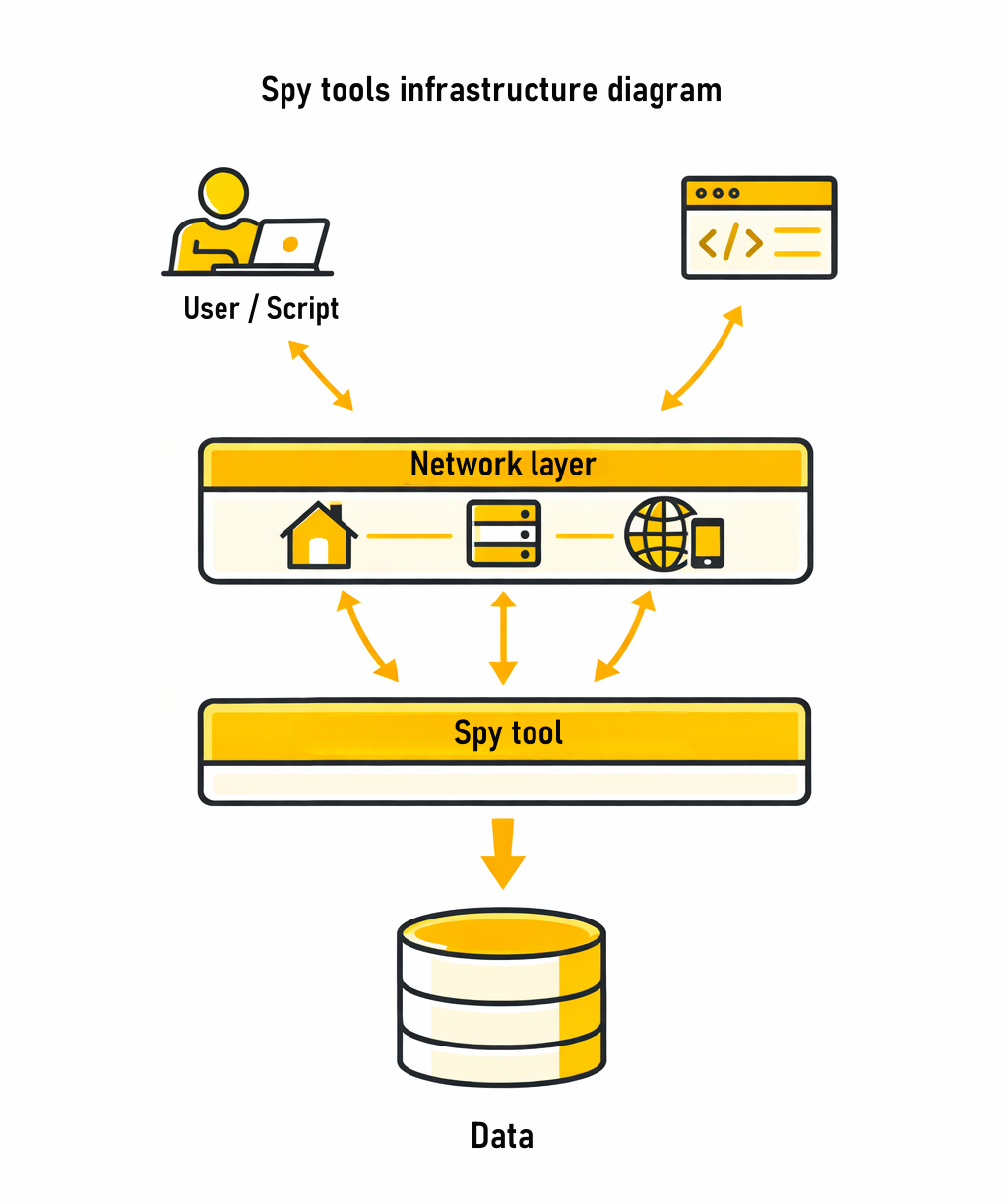
La stabilité ne provient pas d'un seul outil, mais de la structure. Dans les configurations plus matures, l'approche de la recherche elle-même change. Au lieu d'être une action unique, elle est divisée en plusieurs étapes — du filtrage initial et de l'analyse à la collecte de données, la validation répétée et les flux de travail via API.
Chacune de ces étapes crée un type de charge différent, c'est pourquoi elles nécessitent des approches différentes en termes de connexions et de distribution des requêtes. C'est cette séparation qui permet au système de rester stable à mesure que le volume augmente.
Adapter les types de proxys aux tâches
L'un des facteurs clés est l'alignement des types de proxys avec des cas d'utilisation spécifiques.
En pratique, les workflows reposent souvent sur des combinaisons :
Proxys résidentiels : pour la recherche large et la collecte de données distribuée.
Proxys ISP : pour des sessions stables et des actions répétées.
Proxys de centre de données (Datacenter) : pour les appels API et les requêtes techniques.
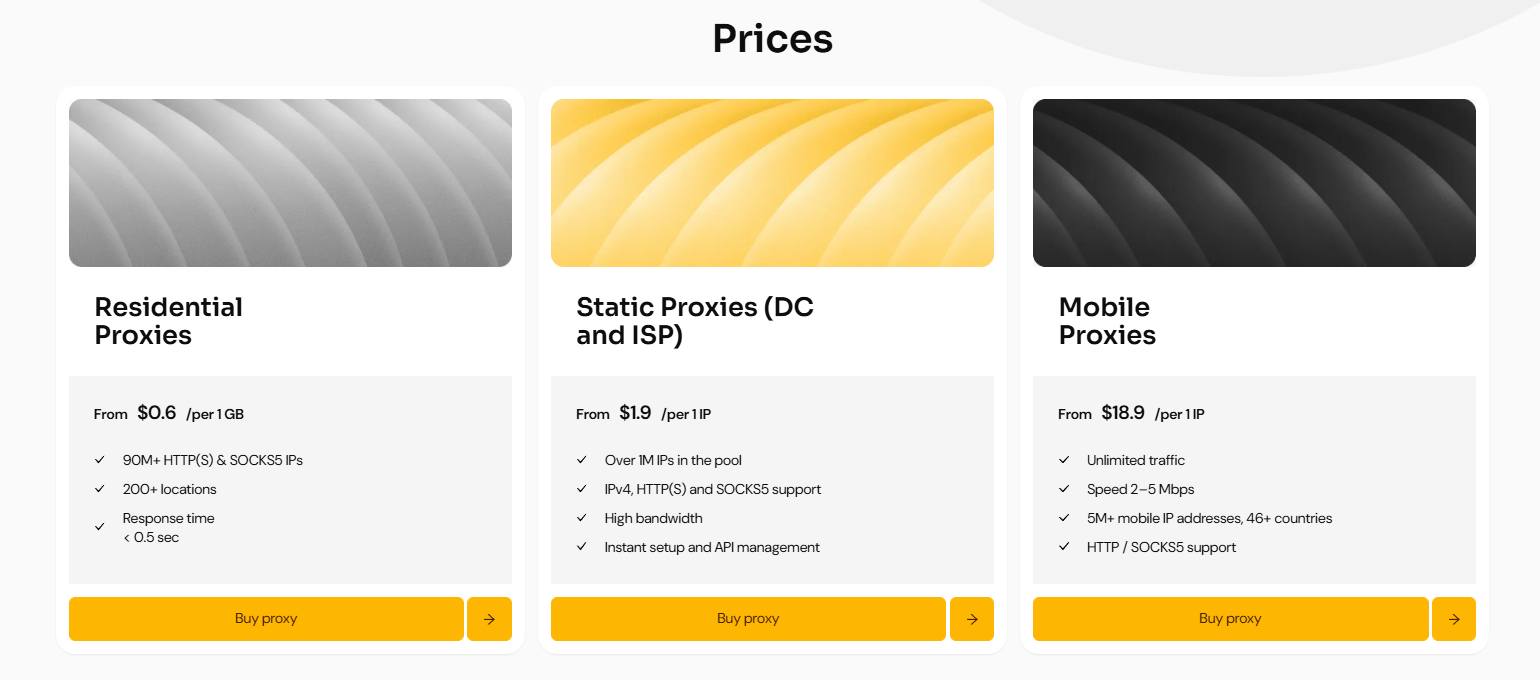
Cette séparation permet d'éviter les conflits de charge et rend le comportement du système plus prévisible. Par exemple, en travaillant avec MangoProxy, ces scénarios peuvent être gérés au sein d'une seule infrastructure sans diviser les processus entre différents services.
Pour les tâches liées aux API et aux requêtes techniques, des proxys de centre de données statiques peuvent être utilisés — avec le code promo SPYHOUSE, une remise de 15% est disponible.
Pourquoi augmenter simplement les requêtes ne fonctionne pas
Lorsque les données deviennent insuffisantes, il est naturel d'essayer d'augmenter le nombre de requêtes. Cependant, sans modifier la logique, cela produit généralement l'effet inverse. La charge commence à se répartir de manière inégale. Certaines IP deviennent surchargées, le trafic est utilisé de manière inefficace, le nombre de requêtes répétées augmente et la stabilité globale du système diminue.
C'est pourquoi le facteur clé n'est pas le volume, mais le contrôle. Ce qui compte, c'est la fréquence d'envoi des requêtes, la manière dont elles sont réparties sur les adresses IP et la structure de la logique de rotation. Ce sont ces paramètres qui déterminent en fin de compte la stabilité du système lors de sa montée en charge (scaling).
Le rôle de la géographie
Un autre facteur important est la géographie.
Dans les outils de spy, les données dépendent souvent de la région, et cela est particulièrement visible lors du travail avec TikTok et les publicités "push". Si toutes les requêtes proviennent d'un seul endroit, certaines combinaisons publicitaires pourraient ne jamais apparaître dans les résultats.
À mesure que la recherche s'étend, cela devient critique. C'est pourquoi les workflows incluent souvent une distribution régionale. L'utilisation de proxys avec une couverture mondiale vous permet de :
comparer les résultats entre différents pays
identifier les modèles publicitaires locaux
construire une vue plus complète des données
Conclusions pratiques
Étendre la recherche publicitaire ne consiste pas à augmenter l'activité, mais à changer d'approche. Un système stable repose sur plusieurs principes fondamentaux : les tâches sont séparées au lieu d'être combinées en un seul processus, les types de connexion sont adaptés aux scénarios spécifiques, la charge est contrôlée et distribuée, et la géographie est prise en compte.
Dans ce contexte, les proxys cessent d'être un outil de support pour devenir une partie intégrante de l'infrastructure. Ils influencent directement la cohérence et la prévisibilité des performances du système à mesure que la charge de travail augmente.
FAQ
Pourquoi les données deviennent-elles moins stables à mesure que le volume de requêtes augmente ?
Parce que la nature de la charge change. Les requêtes deviennent plus fréquentes et répétitives, et sans une distribution appropriée, le système commence à les traiter de manière moins uniforme.
Peut-on utiliser un seul type de proxy pour tout ?
Techniquement oui, mais en pratique cela limite la flexibilité. Différentes tâches — comme l'analyse manuelle, le parsing et l'utilisation d'API — nécessitent des comportements de connexion différents.
Pourquoi certaines données ne se chargent-elles pas ?
Ce n'est généralement pas un problème de l'outil lui-même, mais un problème de surcharge ou de mauvaise distribution des requêtes. Lorsque la charge est inégale, certaines connexions se dégradent et affectent l'exhaustivité des données.
La géographie est-elle importante ?
Oui. Dans les outils de spy, les résultats dépendent souvent de la région. Travailler à partir d'un seul emplacement peut limiter la visibilité de certaines combinaisons publicitaires.
Conclusion
À mesure que le travail avec les outils de spy se développe, le volume de données et les exigences du système évoluent. La stabilité n'est plus une caractéristique par défaut — elle devient le résultat de décisions architecturales. La façon dont les tâches sont structurées, la charge gérée et le trafic distribué définissent en fin de compte l'efficacité de la recherche publicitaire sur le long terme.


Commentaires 0